How ChatGPT Understands Your Questions: From a Beginner's POV
A beginner-friendly walkthrough of how LLMs work, from the Transformer paper to the 2026 model landscape, covering tokenization, self-attention, temperature, model routing, and real-world applications.

Before writing this I took a minute and remembered how I used to think ChatGPT was some kind of magic box that just "knew" stuff. But by time I grew in this field I got to know that LLMs aren't just magic. These are some of the smart mathematical ways to predict the next word, and make language work for us.
As ritual I will be covering few LLM topics here which I use/have used on basis of my projects, paid gigs etc. The complexity of these topics will rise up gradually as the blog continues.
I hope you all know what LLM stands for?
If not no worries, let's start from the very beginning.
What is an LLM?
LLM stands for Large Language Model. The name itself tells you the story. It is Large because it contains hundreds of millions, sometimes hundreds of billions, of parameters. These parameters are like tiny knobs inside the system that get adjusted during training. It is a Language model because it works with human language - English, Hindi, Tamil, or any other language you can think of. And it is a Model because it is a mathematical representation that tries to predict what word should come next in a sentence.
In very simple terms, an LLM is a computer program that has read a very large portion of the internet, books, articles, and code. After reading so much, it learns patterns. When you ask it something, it does not "think" like a human, but it predicts the most suitable words to reply to you, one word at a time.
You might get a question, if it is just predicting the next word, how does it give such long and sensible replies?
Well, it does this over and over again. It predicts one word, adds that word to the sentence, then uses the updated sentence to predict the next word. This loop continues until the model decides the response is complete.
An LLM does not think like a human. It predicts the most probable next word, one token at a time, based on everything it has read. That simple loop, repeated billions of times during training, is what creates the illusion of understanding.
Popular Examples of LLMs
By now you have definitely heard a few of these names:
- ChatGPT by OpenAI - The one that started the whole AI chat trend in 2022. Built on the GPT series of models.
- Claude by Anthropic - Known for safety-first design and long context windows. Popular among researchers and professionals.
- Gemini by Google - Deeply integrated with Google Search, Gmail, and Android devices. Very strong with images and videos.
- Llama by Meta - Open-weight models that anyone can download and run on their own machine. Great for privacy and custom projects.
- DeepSeek by DeepSeek AI - An open-weight contender from China that competes with the best closed models.
All of these are LLMs at their core. They may have different strengths and styles, but the underlying idea is the same: predict the next token.
What Problems Do LLMs Solve?
LLMs are not just for chatting. They solve real, everyday problems that people face constantly.
Think about a student who is struggling to understand a difficult chapter. An LLM can explain the same concept in simpler words, or in the student's mother tongue, without any teacher being available at midnight.
Think about a small business owner who needs to reply to fifty customer emails every morning. An LLM can draft polite, helpful responses in seconds, saving hours of work.
Think about a programmer who is stuck on a bug at 2 AM. An LLM can read the error message, look at the code, and suggest what might be wrong.
Think about someone who moves to a new city and does not know the local language. They can speak in their own language, and the LLM can translate instantly.
These are not science fiction stories. This is happening right now in homes, offices, schools, and hospitals across the country.
Common Applications in Daily Life
You might not realise it, but LLMs are already around you every single day:
- When your phone keyboard predicts the next word you are typing, that is an LLM.
- When Gmail suggests a full sentence to complete your email, that is an LLM.
- When you ask Siri or Google Assistant something and it actually understands your accent, that is an LLM.
- When you get a quick summary of a long article or a meeting transcript, that is an LLM.
- When customer support chatbots actually understand your problem instead of giving generic replies, that is an LLM.
What Happens When You Send a Message to ChatGPT?
So you open ChatGPT, type "Explain gravity to a 5 year old", and press enter. What actually happens between you pressing enter and the reply appearing on your screen? Let's break it down step by step.
Step 1: Typing a Prompt
Your prompt is the text you type into the chat box. It can be a question, a command, a paragraph of context, or even a messy mix of all three. The prompt is the only thing the model uses (along with the conversation history) to figure out what you want.
Step 2: Processing Your Message
Once you hit enter, your message is sent to OpenAI's servers (or whichever company's servers host the model). The first thing that happens is tokenization, which we will cover in detail in the next sections. For now, just know that your text gets broken into small chunks called tokens.
Each token is converted into a number, because computers can only work with numbers. These numbers form a big list that represents your entire message in mathematical form.
Step 3: Generating a Response
Now the model starts its work. It looks at all the token numbers from your prompt and begins predicting what token should come next. It does not predict the entire reply at once. It predicts one token, adds it to the sequence, feeds the new longer sequence back into itself, and predicts the next token. This loop runs until the model generates a special "stop" token that signals the response is complete.
This process is called autoregressive generation. Auto meaning self, regressive meaning looking back at what was already generated. The model is literally feeding its own output back into itself to decide what comes next.
Step 4: Why Responses Are Not Copied from the Internet
Many people think ChatGPT searches the internet and copies text from somewhere. That is not how it works.
During training, the model read a massive amount of text from the internet, books, and articles. It learned patterns, relationships between words, grammar rules, facts, and even some reasoning. But it does not store the internet like a database. It stores the patterns.
When you ask a question, the model is not searching anywhere. It is using the patterns it learned to mathematically generate a response token by token. That is why you can ask it completely new questions that nobody has ever asked before, and it will still give you a coherent answer.
ChatGPT does not have a database of answers to look up. It generates every response from scratch, one token at a time, using patterns it learned during training.
Why Computers Don't Understand Human Language
Here is a truth that surprises many beginners: computers do not understand text at all. They literally cannot read.
Text vs Numbers
At the hardware level, a computer only understands two things: 0 and 1. Every single thing your computer does - playing a video, running a game, or showing this blog - boils down to millions of tiny electrical switches turning on (1) and off (0).
Human language is made of letters, words, sentences, and paragraphs. A computer has no natural way to handle these. A word like "apple" means nothing to a CPU. It is just a sequence of symbols that the computer cannot do math with.
Why Conversion to Numbers Is Needed
Since computers can only do math, and language is made of text, we need a bridge between the two. That bridge is converting text into numbers.
The idea is simple: assign a unique number to every word, or better yet, to every small chunk of text. Once everything is a number, the computer can perform calculations on it. It can multiply, add, compare, and find patterns, all using the math it is built for.
Introduction to Tokens
This is where tokens come in. A token is the smallest unit of text that the model works with. Instead of converting full words or sentences directly into numbers, we first break the text into tokens, and then convert each token into a number.
Think of tokens like the atoms of language for an LLM. Just like everything in the physical world is made of atoms, every piece of text you send to an LLM is made of tokens. And just like atoms combine to form molecules, tokens combine to form meaning.
But what exactly is a token? Let's dig deeper into that.
Tokenization: Breaking Text into Pieces
What Are Tokens?
A token is a chunk of text that the LLM treats as one single unit. It could be a full word, part of a word, a single character, or even just a punctuation mark.
Here is the key thing: tokens are not the same as words.
Words vs Tokens
If English had one token per word, things would be simple. But it does not work that way. Different tokenizers break text differently. Let me show you some examples.
Take the sentence: "I love eating apples."
A word-based split would give you 4 units: ["I", "love", "eating", "apples"]. But an actual LLM tokenizer might split it like this:
"I"-> 1 token" love"-> 1 token (note the leading space, most tokenizers keep spaces as part of tokens)" eating"-> 1 token" apples"-> 1 token
So far it looks like words. But now consider a trickier example: "ChatGPT understands tokenization."
A real tokenizer might split this as: ["Chat", "G", "PT", " understands", " token", "ization", "."] - that is 7 tokens for what most people would count as 3 words.
Why does this happen? Because the tokenizer was trained to find the most efficient way to represent text. Common words like "the" or "and" become single tokens. Rare or complex words get split into smaller pieces. Even "ChatGPT" gets broken up because the tokenizer sees "Chat", "G", and "PT" as more common patterns.
Why Tokenization Is Needed
The reason is purely mathematical. An LLM has a fixed vocabulary size - let's say 50,000 tokens. If it tried to store every possible English word, it would need millions of entries just for English alone, and many of them (like "disestablishmentarianism") would almost never be used. But with subword tokenization, those 50,000 tokens can represent any word in any language by combining smaller pieces.
It is like having a box of lego blocks. You do not need a separate block for every possible shape. You just need a few basic block types, and you can build anything by combining them.
Simple Examples
Here are a few more examples of how text gets tokenized:
| Input Text | Tokens (approximate) | Token Count |
|---|---|---|
| "Hello" | ["Hello"] | 1 |
| "Hello world" | ["Hello", " world"] | 2 |
| "unbelievable" | ["un", "believe", "able"] | 3 |
| "I am from Mumbai" | ["I", " am", " from", " Mumbai"] | 4 |
| "ChatGPT is amazing!" | ["Chat", "G", "PT", " is", " amazing", "!"] | 6 |
Notice how a simple word like "Hello" is 1 token, but "unbelievable" becomes 3 tokens because "un", "believe", and "able" are all common subword patterns that the tokenizer already knows.
A token is not a word. It is the smallest chunk of text that the model processes. A single word can be one token, or it can be broken into multiple tokens.
Transformers: The Engine Inside Every LLM
So far we have covered what an LLM is and how text gets converted into tokens. Now let's talk about the actual engine that processes those tokens and generates a response. That engine is called a Transformer.
What Is a Transformer?
A Transformer is a type of neural network architecture. In plain words, it is a specific mathematical design for how the model's layers are arranged and how they talk to each other.
The Transformer was introduced in 2017 by a team at Google in a paper called "Attention Is All You Need." Yeah, that is the actual title. At that time, nobody knew that this twelve-page paper would completely change how machines understand human language.
Why It Changed AI
Before Transformers, machines used to read sentences word by word, like a person reading with one finger on the page. These older architectures were called RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory). They had two big problems:
- They were slow. Since they processed one word at a time, you could not speed things up by processing multiple words in parallel.
- They forgot things. By the time an RNN reached the end of a long paragraph, it had often "forgotten" what was said at the beginning.
The Transformer solved both problems with one simple idea: instead of reading word by word, look at the entire sentence at once.
How It Helps Understand Language: Self-Attention
The core innovation of the Transformer is something called self-attention. Here is what it does: every word in a sentence can directly "pay attention" to every other word in that same sentence, all at the same time.
Imagine you are reading the sentence: "The cat sat on the mat because it was tired."
When you read the word "it," your brain immediately knows "it" refers to "the cat." Self-attention does exactly this. It creates a direct connection between "it" and "cat" no matter how far apart they are in the sentence.
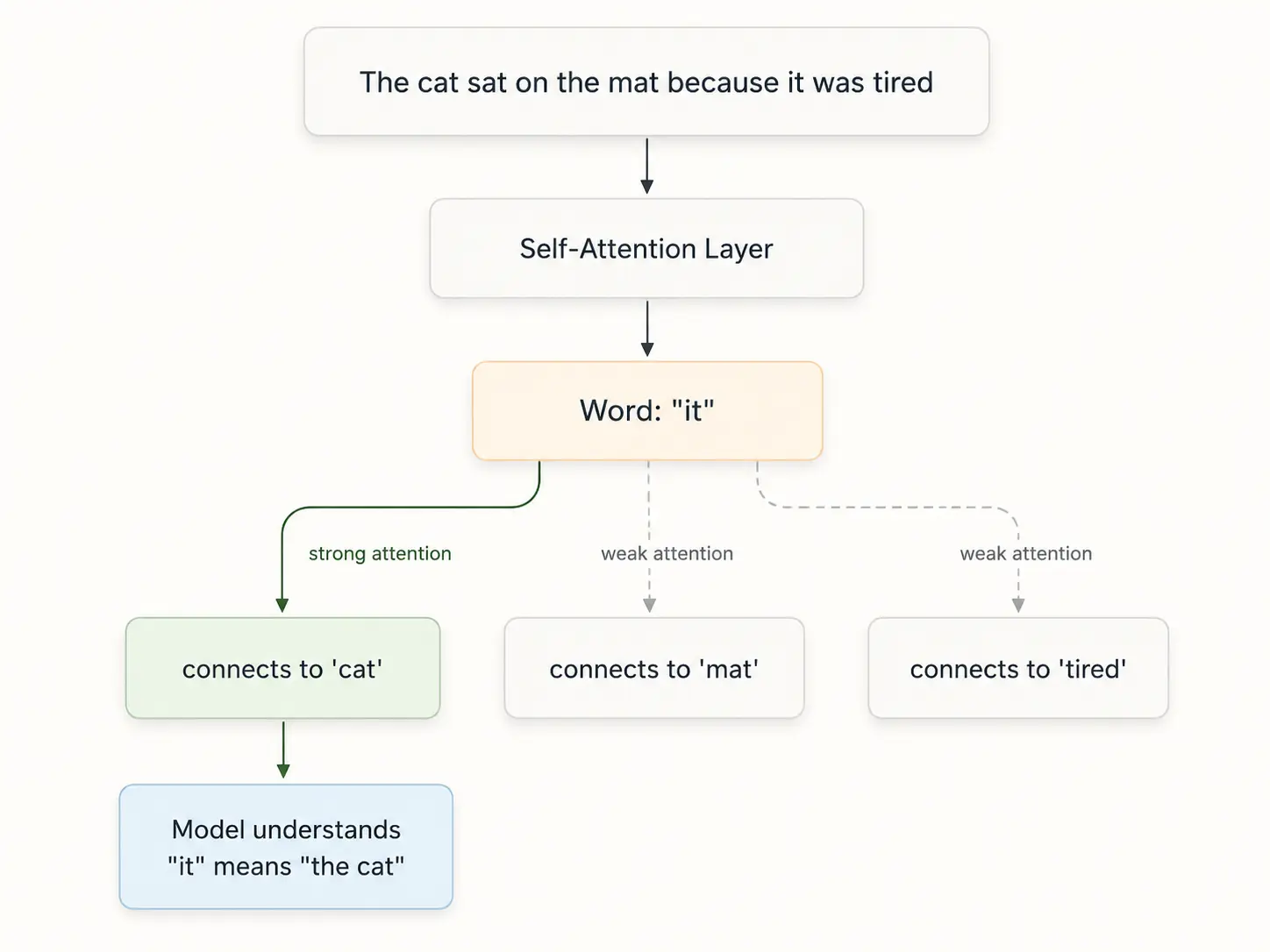
Because every word can look at every other word directly, the model never "forgets" what was said earlier. It can understand that "it" means "the cat" even if there are fifty words between them.
Why Almost Every Modern LLM Uses Transformers
There are three big reasons:
- Parallel processing. Unlike RNNs that had to go step by step, Transformers can process all tokens in a sequence at the same time. This makes training much faster.
- Long-range understanding. Self-attention means the model can connect ideas that are thousands of tokens apart. This is why ChatGPT can remember something you said at the very start of a long conversation.
- Scalability. Transformers scale incredibly well. Add more layers, more parameters, more data, and the model keeps getting better. This property is what allowed models to go from millions of parameters to hundreds of billions.
Simply put, the Transformer is the reason we moved from chatbots that could barely hold a three-message conversation to agents that can plan across multiple stages and write thousands of lines of code.
Temperature and Context Window: Two Hidden Dials
There are two important settings that control how an LLM behaves when generating responses. You do not see them when you use ChatGPT, but they are always running behind the scenes.
What Is Context Window?
The context window is the maximum amount of text (measured in tokens) that the model can "see" at any given moment. Think of it like the model's short-term memory.
If a model has a context window of 128,000 tokens, it means it can consider up to 128,000 tokens of conversation history when generating the next token. Anything beyond that falls out of the window and is forgotten.
This is why very long conversations with ChatGPT sometimes lose track of things you said at the beginning. The older messages have fallen out of the context window.
In 2026, many models offer context windows of 1 million tokens or more. That is roughly the length of all three Lord of the Rings books combined.
What Is Temperature?
Temperature controls how random or creative the model's output is. It is a number typically between 0 and 2.
When the model predicts the next token, it actually calculates a probability score for every token in its vocabulary. With low temperature, it almost always picks the highest-probability token. With high temperature, it is more willing to pick less likely tokens, which makes the output more varied and creative.
Low Temperature (e.g., 0.2): The model sticks to safe, predictable responses. Good for factual tasks like summarisation, code generation, or answering questions where accuracy matters most.
High Temperature (e.g., 1.2): The model takes more risks and picks less obvious tokens. Good for creative tasks like storytelling, poetry, or brainstorming ideas. But too high, and the output becomes random nonsense.
The Complete LLM Workflow: Putting It All Together
Now that we have covered all the individual pieces, let's see how they fit together end to end.
When you send a message to ChatGPT, here is the complete journey it takes:
- You type a prompt and press enter.
- Tokenization: Your text is broken into tokens. Each token gets mapped to a number from the model's vocabulary.
- Embedding: Each token number is converted into a dense vector (a long list of decimal numbers) that captures the meaning of that token. Words with similar meanings get similar vectors.
- Positional Encoding: Since Transformers process all tokens at once, they need a way to know which token comes first, second, third, and so on. Positional encoding adds this order information to the embeddings.
- Transformer Layers: The embedded tokens pass through multiple Transformer layers. In each layer, self-attention lets every token look at every other token to understand context. Feed-forward layers then process this enriched information.
- Output Projection: After the final Transformer layer, the model produces a probability score for every token in its vocabulary. This is a list of 50,000+ numbers saying how likely each token is to come next.
- Sampling: Based on the temperature setting, the model picks the next token. Low temperature picks the highest probability token. High temperature rolls the dice a bit.
- Autoregressive Loop: The chosen token is added to the sequence, and the whole process repeats from step 3 until a stop token is generated.
- Detokenization: The generated token numbers are converted back into readable text.
- The response appears on your screen.
All of this happens in under a second for a short reply. Every time you see ChatGPT typing word by word, what you are really watching is tokens being generated one by one through this pipeline.
From Research Paper to Real Products (2017 to 2026)
After the 2017 paper, things started moving very fast:
- 2018: Google released BERT, which read text in both directions to understand context better. It was great for tasks like searching and classifying text.
- 2018-2019: OpenAI released GPT and GPT-2. These were decoder-only models focused on generating text. GPT-2 was so good at writing that OpenAI initially hesitated to release the full version.
- 2020: GPT-3 arrived with 175 billion parameters. It could write essays, answer questions, translate languages, and even write simple code, all without being specifically trained for each task.
- 2022: ChatGPT was launched. It was basically GPT-3.5 fine-tuned with human feedback. Suddenly, everyone - students, teachers, developers, grandparents - could talk to an AI like a friend.
- 2023-2024: GPT-4, Google Gemini, Anthropic Claude, Meta LLaMA, and many others joined the race. Models became multimodal, meaning they could understand not just text but also images, audio, and even video.
And then came 2025-2026, which honestly feels like the field grew up overnight.
The 2026 Landscape: Where We Are Today
If you are reading this in July 2026, the LLM world looks very different from even two years ago. Let me break down the major players that are actually relevant today:
Claude Fable 5 by Anthropic: Released on June 9, 2026, this is Anthropic's first "Mythos-class" model made available to the public. It ships with a 1-million-token context window and up to 128,000 output tokens per request. What makes it special is that it is built for long-horizon agentic work, meaning it can plan across stages, delegate to sub-agents, and verify its own output. It is positioned as the most capable model for sustained autonomy.
GPT-5.5 and GPT-5 pro by OpenAI: These are OpenAI's current flagship models. GPT-5.5 is known for configurable reasoning effort and broad professional analysis, while GPT-5 pro is positioned for the hardest possible problems with maximum compute per token. GPT-5.5 leads on math benchmarks like AIME 2025 at 95.2%.
Gemini 3.1 Pro by Google: This model is deeply integrated into Google Search, Gmail, and Android phones. It offers a 1-million-token context window and is strongest on multimodal tasks. It can look at images, audio, and video and answer questions about them. It also leads on some reasoning benchmarks like ARC-AGI-2.
Llama 4 Maverick by Meta: This is the current king of open-weight models. You can download it and run it on your own hardware. It offers a 1-million-token context window and is the practical choice for teams that cannot send their data to external APIs.
DeepSeek V4 and Qwen3.6 from Chinese labs: These are serious open-weight contenders that compete with closed frontier models. DeepSeek V4-Pro offers 1M context and MIT licensing, while Qwen3.6-27B can run on a single consumer GPU.
You might get a question, with so many models, how do teams actually decide which one to use?
The Real Trend in 2026: Model Routing
Here is a note from my side: in 2026, the smartest teams are not picking one model. They are building model routing layers that send each task to the right model based on complexity, cost, and capability.
A practical multi-model architecture looks like this:
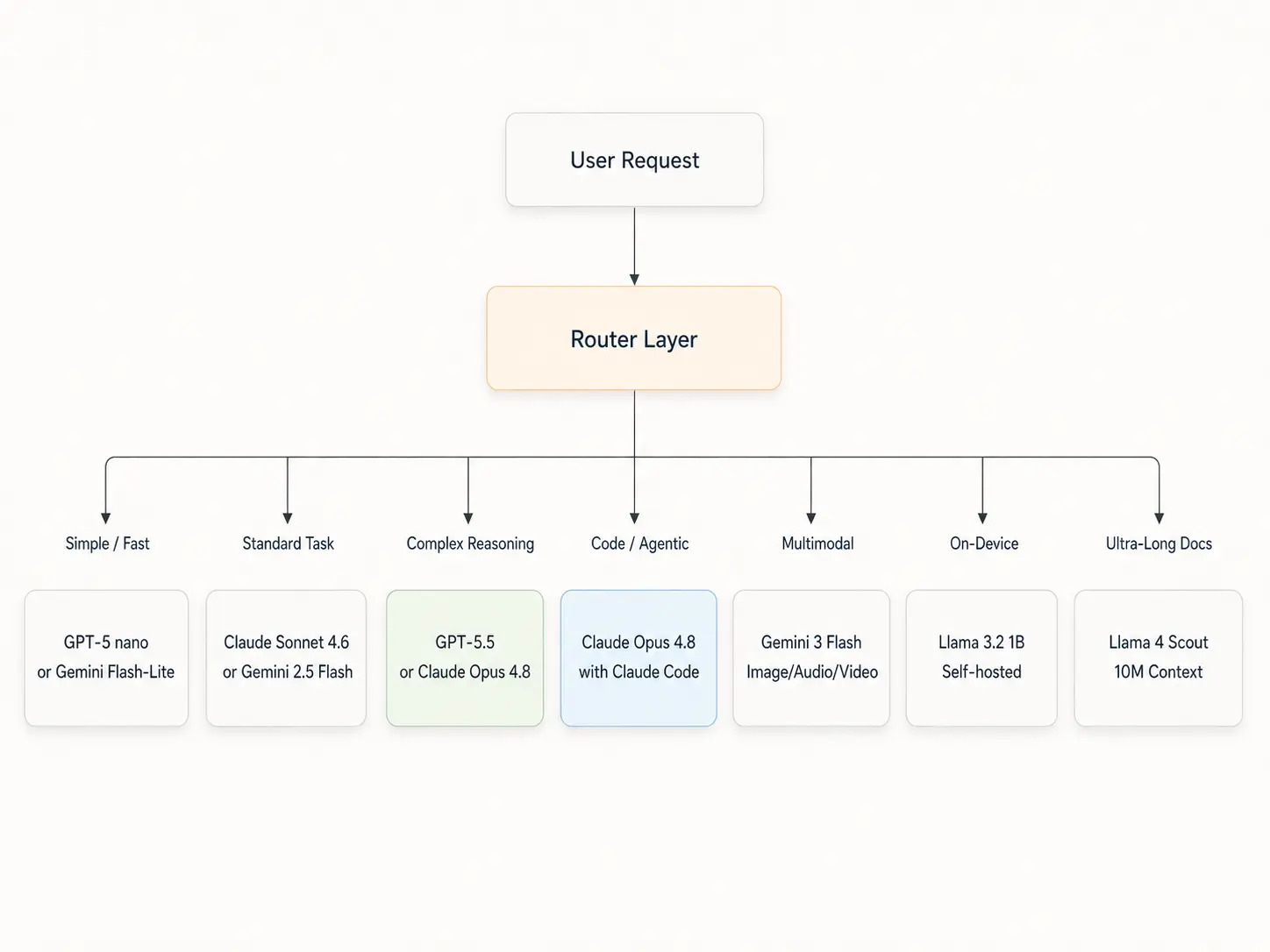
This is not theoretical. It is how the most sophisticated AI teams already operate. The competitive advantage is shifting from "which model is best?" to "which model is best for this specific task?"
Key insight
The smartest teams in 2026 do not pick one model. They build routing layers that match each request to the right model based on complexity, cost, and capability. One query might go to a fast, cheap model. Another might need the full reasoning power of GPT-5.5. The router decides.
The Road Ahead
The journey from "Attention Is All You Need" to today took only nine years. In technology terms, that is incredibly fast. But the most exciting part is that we have already crossed into the agentic era.
Today, LLMs are not just question-answer machines sitting inside a chat window. They are agents that can read your codebase, browse the web, query databases, write files, and execute multi-step plans on your behalf. We are not heading toward this. It is already shipping.
Claude Code by Anthropic is a prime example. It is an agentic coding assistant that reads your entire repository, plans refactors, runs tests, and commits changes while you watch. It does not suggest code. It acts.
OpenClaw is an open-source agentic framework gaining traction in 2026. It connects any LLM to a toolbox of APIs, browsers, and file systems, letting the model browse the web, query databases, and write files without human intervention at every step.
Hermes by Nous Research pushes the boundaries of open agentic reasoning. It thinks through complex tasks step by step, uses tools when needed, and self-corrects when it goes wrong.
You might wonder, if these agents can act on their own, how do we make sure they do not break things?
That is exactly why safety and oversight are the hottest topics right now. Anthropic built Constitutional Classifiers into Claude Fable 5 to prevent jailbreaks. OpenAI introduced deliberative alignment so models reason about safety before they act. The race is no longer just about who builds the smartest model. It is about who builds the most trustworthy agent.
Beyond safety, researchers are also working on making models smaller and faster so they can run on your phone without internet access. Another big focus is cultural understanding. A model trained mostly on Western data may not understand Indian festivals, local customs, or the way we frame our sentences. Building local, homegrown models is essential for this.
From nine years of research, we arrived at agents that think, act, and correct themselves. The models are not just getting smarter. They are getting hands.
Closing Thoughts
The story of LLMs is really a story about how a simple idea - letting words pay attention to each other - changed everything. What started as a research paper in 2017 is now sitting in your phone, helping you write emails, study for exams, and talk to people across language barriers.
An LLM is not a human brain. It does not feel emotions or have real understanding. But it has learned the patterns of human language so deeply that it can assist us in ways that were impossible just a few years ago.
And if the last nine years are any indication, the next nine will be even more surprising. We are moving from chatbots to agents, from asking questions to delegating tasks. The models are not just getting smarter, they are getting hands.
Hope I was able to add some value to your today's learning :)